我都知道的JS
# 我都知道的JS
# for...in和for...of的区别?
for in更适合遍历对象,不要使用for in遍历数组。
for in遍历的是数组的索引(即键名),而for of遍历的是数组元素值。
for of遍历的只是数组内的元素,而不包括数组的原型属性method和索引name
# 介绍模块化发展历程
1. IIFE
自执行函数编写代码,单独作用域,避免变量冲突
2. AMD
requireJS编写代码,特点依赖必须声明好
3.CMD
seaJS编写代码,支持动态引入依赖文件
4.commonJS
nodeJS自带模块化
5. ES6
支持import引入另一个js
# cookie 和 token 都存放在 header 中,为什么不会劫持 token?
cookie:登陆后后端生成一个sessionid放在cookie中返回给客户端,并且服务端一直记录着这个sessionid,客户端以后每次请求都会带上这个sessionid,服务端通过这个sessionid来验证身份之类的操作。所以别人拿到了cookie拿到了sessionid后,就可以完全替代你。
token:登陆后后端不返回一个token给客户端,客户端将这个token存储起来,然后每次客户端请求都需要开发者手动将token放在header中带过去,服务端每次只需要对这个token进行验证就能使用token中的信息来进行下一步操作了。
形象化理解:
cookie 举例:服务员看你的身份证,给你一个编号,以后,进行任何操作,都出示编号后服务员去看查你是谁。
token 举例:直接给服务员看自己身份证。
xss:用户通过各种方式将恶意代码注入到其他用户的页面中。就可以通过脚本获取信息,发起请求,之类的操作。
csrf:跨站请求攻击,简单地说,是攻击者通过一些技术手段欺骗用户的浏览器去访问一个自己曾经认证过的网站并运行一些操作(如发邮件,发消息,甚至财产操作如转账和购买商品)。由于浏览器曾经认证过,所以被访问的网站会认为是真正的用户操作而去运行。这利用了web中用户身份验证的一个漏洞:简单的身份验证只能保证请求发自某个用户的浏览器,却不能保证请求本身是用户自愿发出的。csrf并不能够拿到用户的任何信息,它只是欺骗用户浏览器,让其以用户的名义进行操作。
上面的两种攻击方式,如果被xss攻击了,不管是token还是cookie,都能被拿到,所以对于xss攻击来说,cookie和token没有什么区别。但是对于csrf来说就有区别了。
上面的csrf攻击为例:
- cookie:用户点击了链接,cookie未失效,导致发起请求后后端以为是用户正常操作,于是进行扣款操作。
- token:用户点击链接,由于浏览器不会自动带上token,所以即使发了请求,后端的token验证不会通过,所以不会进行扣款操作。
**总结:**CSRF攻击的原因是浏览器会自动带上cookie,而浏览器不会自动带上token
# 下列代码打印什么?
var b = 10;
(function b(){
b = 20;
console.log(b);
})();
2
3
4
5
6
直接打印b fn
我的理解是,先不看函数自执行,直接fn b() 首先函数声明比变量要高,其次b = 20 没有var 获取其他,说明是window最外层定义的变量。 js作用域中,先找最近的 那就是b fn ,直接打印了,如果 b = 20 有var 那就是打印20
# 下面代码中 a 在什么情况下会打印 1?
var a = ?;
if(a == 1 && a == 2 && a == 3){
console.log(1);
}
2
3
4
5
利用数组 改写toString方法
var a=[1,2,3]
a.toString=a.shift
if(a == 1 && a == 2 && a == 3){
console.log(1);
}
2
3
4
5
利用valueOf ==隐式转换会调用本类型toString或valueOf方法.
var a={
i:1
valueOf(){
return a.i++
}
}
if(a == 1 && a == 2 && a == 3){
console.log(1);
}
2
3
4
5
6
7
8
9
利用toString
上栗valueOf改为toString即可
# splice和slice、map和forEach、 filter()、reduce()的区别
1. splice(start,deleteCount,item1,item2.....);
- items 为要添加的元素
- 由被删除的元素组成的一个数组。如果只删除了一个元素,则返回只包含一个元素的数组。如果没有删除元素,则返回空数组
- 改变原数组,数组长度发生变化
当尝试在 for 循环中删除某个元素时,可以先遍历记录下索引,然后再执行删除操作。再者比较推荐的做法是使用 filter 来做到删除的功能
2. slice(start,end)
- 返回值为截取出来的元素的集合
- 原始数组不会发生变化
3.map()
- 返回新数组,其结果是该数组中的每个元素都调用一次提供的函数后的返回值。
4.forEach()
- 并且不打算改变数据,单纯的只是想用数据做一些事情,他允许callback更改原始数组的元素
5.reduce()
- 接收一个函数作为累加器,数组中的每一个值(从左到右)开始缩减,最终计算一个值
- 不会改变原数组的值
6.filter()
- 方法创建一个新数组
- 新数组中的元素是通过检查指定数组中符合条件的所有元素。它里面通过function去做筛选的操作
7.其他一些数组方法扩展
- push / pop 在数组末尾增/删元素;
- unshift / shift 在数组首部增/删元素;
- concat 把一个(或多个)数组和(或)值与原数组拼接,返回拼接后的数组
- join() 把数组的所有元素放入一个字符串。元素通过指定的分隔符进行分隔
- reverse() 颠倒数组中元素的顺序
# 实现 (5).add(3).minus(2) 功能。
Number.prototype.add=function(n){
return this+n
}
Number.prototype.minus=function(n){
return this-n
}
console.log((5).add(3).minus(2))
2
3
4
5
6
7
总结:从外到内,再从内到外
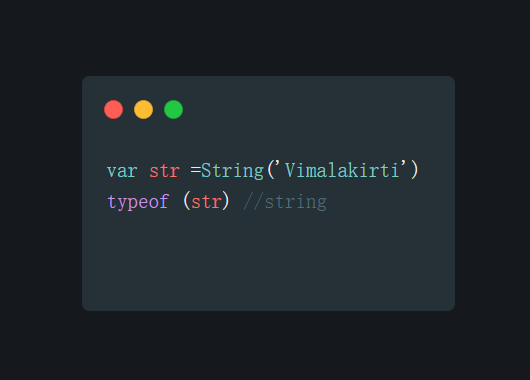
# JS String 和 new String的区别
当通过new 调用 String()时,返回的是一个object

当通过字面量或者直接调用String(),返回的是一个字符串
# 实现add函数,让add(a)(b)和add(a,b)两种调用结果相同
function add(a,b) {
if(!b){
return function (x){
return a+x
}
}
return a+b
}
2
3
4
5
6
7
8
# 如何让:a == 1 && a == 2 && a == 3
const a = {
value:[3,2,1],
valueOf:function(){
//隐式转换调用 valueOf ,pop()删除数组最后一个元素,改变原数组,返回被删除的元素.
return this.value.pop()
}
}
2
3
4
5
6
7
# 如何让事件先冒泡后捕获
根据 w3c 标准,事件是先捕获,后冒泡的,若要实现事件先冒泡后捕获,给一个元素绑定两个 addEventlistener,其中一个第三个参数设置为 false(也即默认冒泡) ,另一个设置 true ,调整代码顺序, 设置 false 的事件放于设置 true 的前面。
# 防抖和节流
防抖:一个有着原则的程序员,必须确保一定的休息时间,期间啥事也不管,有人打扰则重新计算休息时间。休息期间吃饱喝足了才开工。(写了一句代码,必须休息两个小时,谁来打扰,则重新开始休息两小时)
const debounce = (fn, delay=500) => {
let timer = null;
return (...args) => {
clearTimeout(timer);
timer = setTimeout(() => {
fn.apply(this, args);
}, delay);
};
};
2
3
4
5
6
7
8
9
防抖使用场景:input 输入事件,窗口resize
节流:一个没有感情的程序员,在一定的时间内只会写一句代码,不管多少需求堆积,因为必须保证其余时间充分的摸鱼。(两小时内只写一句代码,其余的时间保证充分摸鱼)
const throttle = (fn, delay = 500) => {
let flag = true;
return (...args) => {
if (!flag) return;
flag = false;
setTimeout(() => {
fn.apply(this, args);
flag = true;
}, delay);
};
};
2
3
4
5
6
7
8
9
10
11
节流使用场景:scroll事件
# 闭包
有权访问另一个函数内部的变量的函数,也可以说函数 B 被作为函数 A 的返回值,并在外部被引用,那么函数 B 就被称为闭包。
function funcFactory () {
var a = 1;
return function () {
console.log(a);
}
}
// 闭包
var sayA = funcFactory();
sayA();
2
3
4
5
6
7
8
9
10
# es6的新特性都有哪些
- let、const 声明都有块级作用域,const声明就需赋值
- 可以给形参函数设置默认值
- 扩展运算符
- 解构赋值
- 箭头函数,相当于匿名函数,不能用于构造函数,不能被new。没有自己的this,不能用call、apply、bind改变箭头函数的this
# 你是如何理解原型和原型链的
在js中,每个对象都有一个隐式原型,即 proto 属性,指向创建这个对象的构造函数的原型对象
当我们访问对象的某个属性或方法时,如果对象自身没有属性或方法,那么就会沿着 proto 从他的原型对象上找,一直追溯到object.prototype对象还未找到的话,就会返回 undefined,这就是原型链的工作原理
把所有的对象共用的属性全部放在堆内存的一个对象(共用属性组成的对象),然后让每一个对象的 __proto__存储这个「共用属性组成的对象」的地址。而这个共用属性就是原型,原型出现的目的就是为了减少不必要的内存消耗。而原型链就是对象通过__proto__向当前实例所属类的原型上查找属性或方法的机制,如果找到Object的原型上还是没有找到想要的属性或者是方法则查找结束,最终会返回undefined
# 浏览器渲染的主要流程是什么
将html代码按照深度优先遍历来生成DOM树。 css文件下载完后也会进行渲染,生成相应的CSSOM。 当所有的css文件下载完且所有的CSSOM构建结束后,就会和DOM一起生成Render Tree。 接下来,浏览器就会进入Layout环节,将所有的节点位置计算出来。 最后,通过Painting环节将所有的节点内容呈现到屏幕上。
具体流程:
- 解析html构建DOM树:渲染引擎解析HTML文档,首先将标签转换成DOM树中的DOM node(包括js生成的标签)生成内容树;
- 构建render树:解析对应的css文件(包括js生成的样式和外部引入样式),将DOM树和CSSOM树结合,生成渲染树(Render Tree)
- 布局渲染树:从根结点递归调用,计算每一个元素的大小位置等,给出每个节点的精准位置
- 绘制渲染树:遍历渲染树,绘制出每一个节点
简析:解析HTML构建dom树->构建渲染树->布局渲染树->绘制渲染树
尽量不使用table布局
由于浏览器使用流式布局,对Render Tree的计算通常只需要遍历一次就可以完成,但table及其内部元素除外,通常需要多次计算且要花费3倍于同等元素的时间,这也是为什么要避免使用table布局的原因之一