工程化
# 什么是前端工程化
前端工程化是指围绕代码处理的一系列工具链,他们把代码当作字符串处理,并不关心代码的内容,包括编译构建、静态分析、格式化、CI/CD等等。
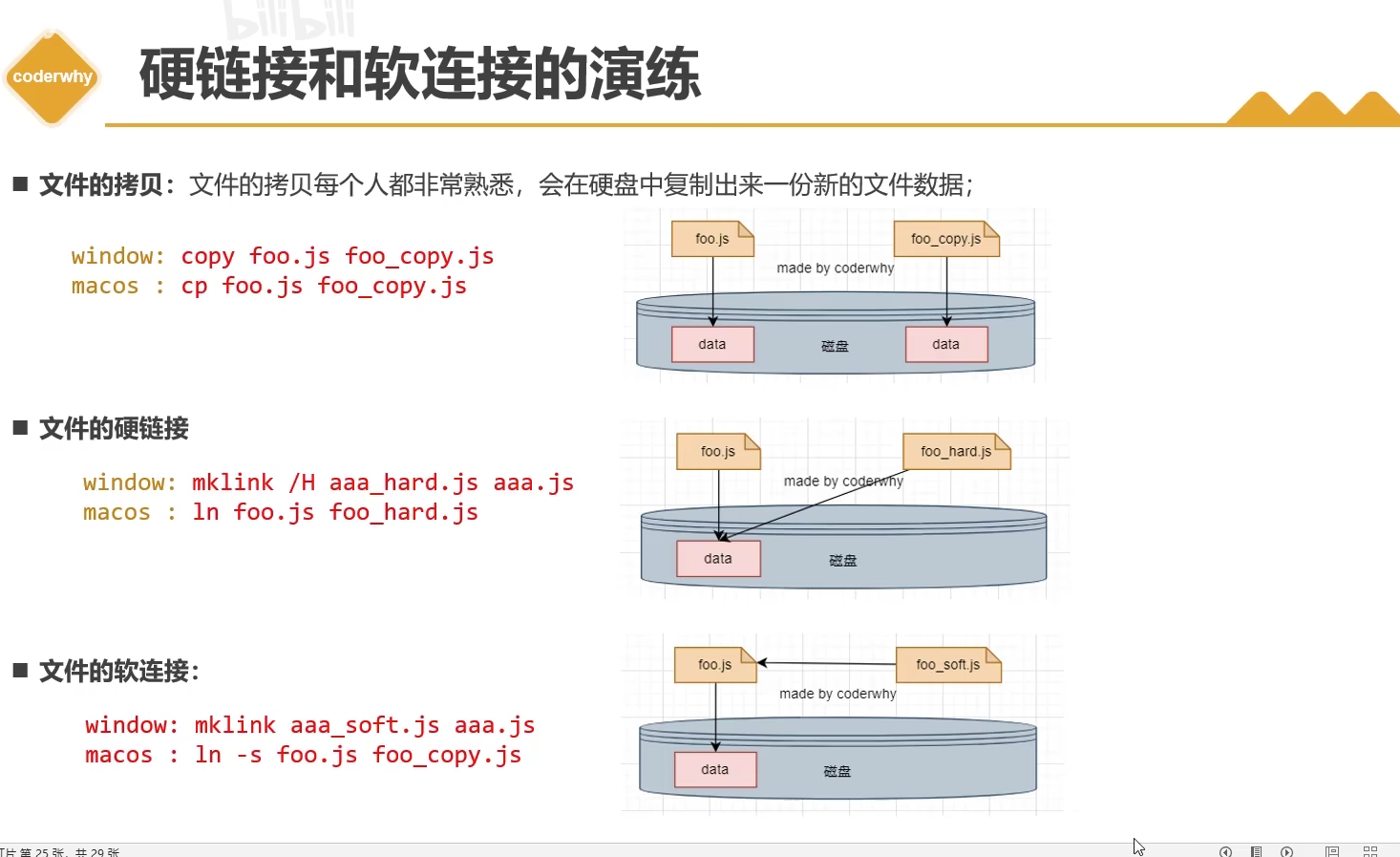
# 软连接与硬连接
# pnpm 常用命令

# 组件封装
组件封装原则:
一个组件只专注做一件事,且把这件事做好(通用 易用 可组合):
- 功能上拆分层次
- 尽量让组件原子化(便于使用者自己组合)
- 容器组件(只管理数据)&UI组件(只显示视图)
针对于业务,尽量做到组件的原子化,而不是做大而全的组件,考虑后续的扩展性及维护成本以及使用者的心智负担
vue组件三要素:
- props参数
- slot定制插槽
- event自定义事件
组件封装思想:
- 判断基本类型
- 哪些写死
- 哪些传进来
- 扩展
- 自定义事件,判断传出参数
- 插槽扩展
- 优化
- 提高适应性(v-if,v-show,component 动态组件)
使用者的学习成本
- 是否增加额外的心智负担
- 有无配套的使用文档及示例
# 解释一下CI/CD
持续集成和持续交付/部署
- 持续集成:开发人员提交代码后,自动化构建,自动化测试和自动化部署。
- 持续交付/部署:经过持续集成的代码(经测试过,并通过了品质保证的软件代码),自动化的部署至生产环境中
提高开发项目的质量,降低风险和加速交付时间,提高开发效率、质量和团队协作能力。
# 了解 tree shaking 吗,说说他的实现原理
摇树优化(tree shaking)是一种能够将没有用到的代码在编译阶段自动去除的优化技术,主要目的是减小浏览器中加载 javascript 的代码体积,从而提高网站性能。
其实现原理主要是利用了es6模块化规范中的静态引用关系,即在静态分析阶段(不需要真正运行代码)就能知道一个模块是否被导出使用,javascript利用这些信息来剔除没被使用的代码,从而做到减小生成的 bundle 大小。
具体实现过程如下:
- 遍历源码中所有模块以及她们的导入关系,生成一张完整的依赖树
- 对于应用入口文件的依赖项进行分析,找出其中没有被用到的导出项
- 去除没有被用到的导出项
需要注意的是,tree shaking 并不是完美的,它有一些限制。例如,如果一个模块导出的是一个对象或类,而这个对象或类的某些属性或方法被其他模块使用,那么整个对象或类都不会被 tree shaking 删除。因此,为了使 tree shaking 生效,我们需要尽可能地将模块拆分成更小的单元,并将不同的模块之间的依赖关系尽可能明确地声明出来。
# Babel是什么?能说说他的原理实现吗
babel 是一个广泛使用的 Javascript 编译器,可以将 es6及以上的代码转换为向后兼容的代码。
原理实现:
- 解析:babel 会先使用插件将源代码解析为 ast
- 词法分析:将源代码分解为 token(如变量名、运算符等)
- 语法分析:将词法分析产生的词法单元转化为AST
- 转换:遍历得到的 ast,对其进行修改和重构,包括添加、删除、替换、移动节点等操作
- 生成:将转换后的 ast 重新生成为代码
# eslint 原理实现
解析js生成token,词法分析,语法分析,再转化为抽象语法树ast,根据配置的rules,将AST与规则进行匹配,检查代码是否符合规范
ESLint 是一款可配置的 JavaScript 代码检测工具,可以帮助开发者保持代码风格的一致性,规避潜在的错误和代码质量问题。它的原理基于以下三个步骤:
- 代码解析:ESLint 使用 Esprima 将代码解析成一个抽象语法树(AST),以便进行后续的检测和修复。同时,还可以使用不同的解析器来支持不同的 JavaScript 语法。
- 规则匹配:ESLint 根据用户在配置文件中定义的规则,匹配检测代码中存在的问题,并生成一份问题清单。这些规则可以是官方的也可以是自定义的。其中,每个规则都是一个函数,用来检测 AST 中的节点是否符合规定的规则。
- 输出结果:ESLint 根据检测结果,生成一份报告,指出代码中的问题。这个报告可以在控制台输出,也可以配置输出到指定的文件中。
在实现规则匹配时,ESLint 提供了一些钩子函数和 API,方便插件和规则的开发。并且还支持通过配置项对插件和规则进行启用和禁用、调整检测顺序等操作,可以更加灵活地适应各种项目的需求和场景。 需要注意的是,ESLint 本身只是一个坚持规范和风格的工具,并不会自动修复代码问题。因此,开发者需要通过配合使用其他工具(如 Prettier、lint-staged 等)来对代码进行格式化和修复,以便提高开发效率和代码质量。